TinyWorld TinyFish Hackathon
Last updated: May 10, 2026
Tools: TinyFish · NetworkX · Wikidata
TinyWorld searches a person and builds a knowledge graph of who they are: schools, employers, teams, events, key associates. Search two people and it surfaces the shortest path between them through shared entities. The demo joke is “find out if you’re dating your cousin.” The actual product underneath is KYC: when banks, insurers, and onboarding teams ask “is this counterparty closer to my customer than they should be,” they want exactly this. Built at the TinyFish hackathon in Singapore, my first time using autonomous browser agents.
What it does
Search a name and TinyWorld fans out across Wikipedia, Wikidata, and a TinyFish stealth browser running deep searches across Google, social profiles, and news. The agent’s live browser stream is exposed in the UI so you can watch the search happen in real time. Everything that comes back gets passed to an LLM that extracts structured fields (schools, companies, locations, key associates), and the result becomes a node in a knowledge graph alongside one node per school, company, team, event, and location.
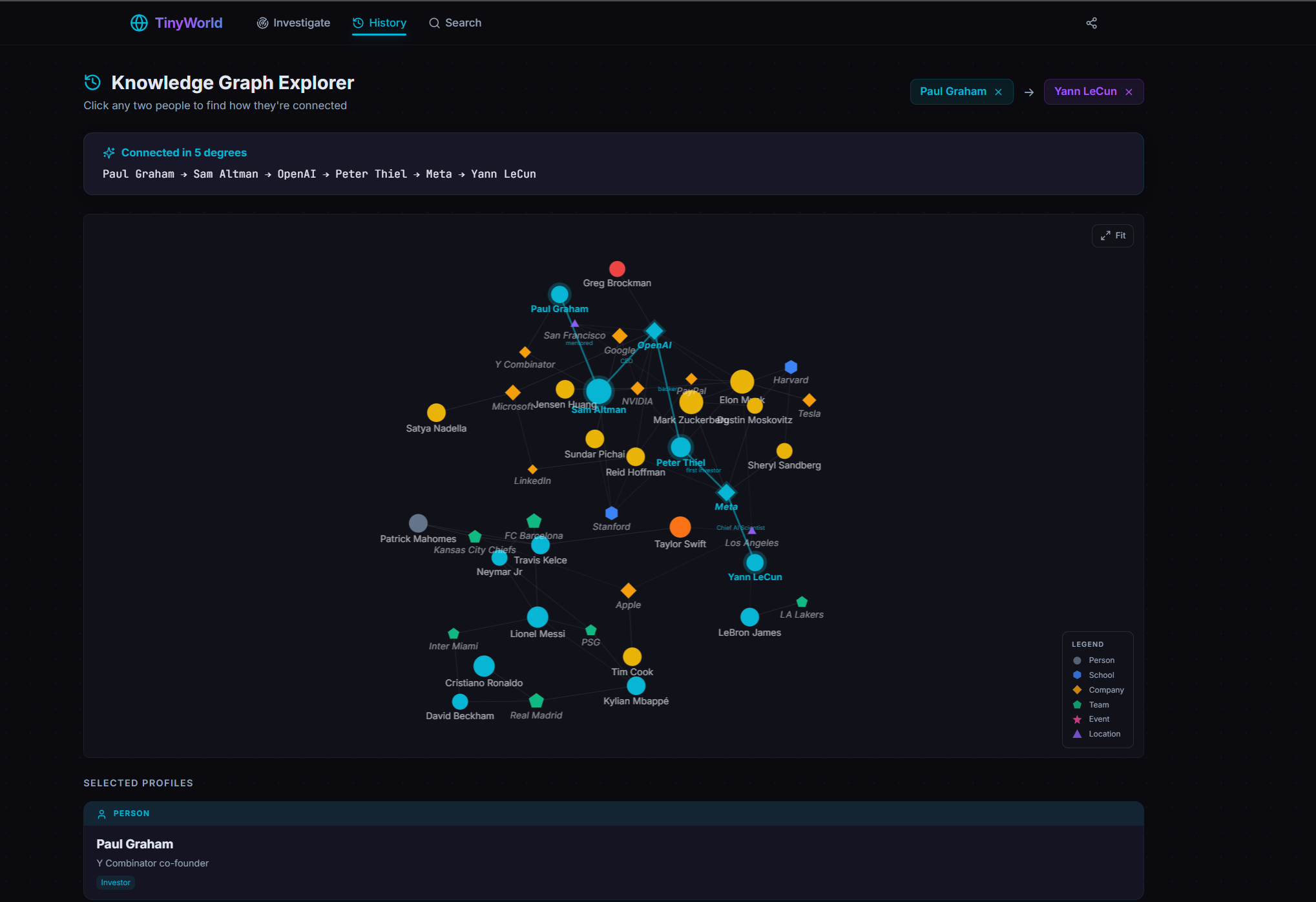
Search two people and TinyWorld looks for a shortest path between them through shared entities. The output is a graph with the path highlighted, plus a natural-language summary of how the connection works.
How it works
Three layers, cheap to expensive.
A search for one person fans out in parallel: Wikipedia for the structured biography, a Wikidata SPARQL query for birth date, occupations, education, and organisations, and a TinyFish stealth browser running a deep search across Google, social profiles, and news. Everything that comes back gets dumped into one blob, and an LLM extracts the structured fields. The person becomes a node, every school, company, team, event, and location becomes its own node, and the person-to-entity edges get relationship types like attended, works_at, member_of, located_in. The whole thing lives in an in-memory NetworkX graph, mirrored to SQLite so it survives a restart.
Connecting two people is a cascade. Layer 1 is a NetworkX shortest-path lookup on the existing graph. If A and B already share a school or a company node from previous searches, you have a path in milliseconds. If not, layer 2 expands both people’s neighbourhoods by pulling related people from Wikidata (top ten each) and re-runs shortest path. Only if both layers fail does layer 3 fire: a TinyFish deep connection search for co-mentions, shared entities, and shared events, plus a Google fallback. An LLM reads the dump, proposes bridge entities, those become new nodes, and shortest-path runs one last time.
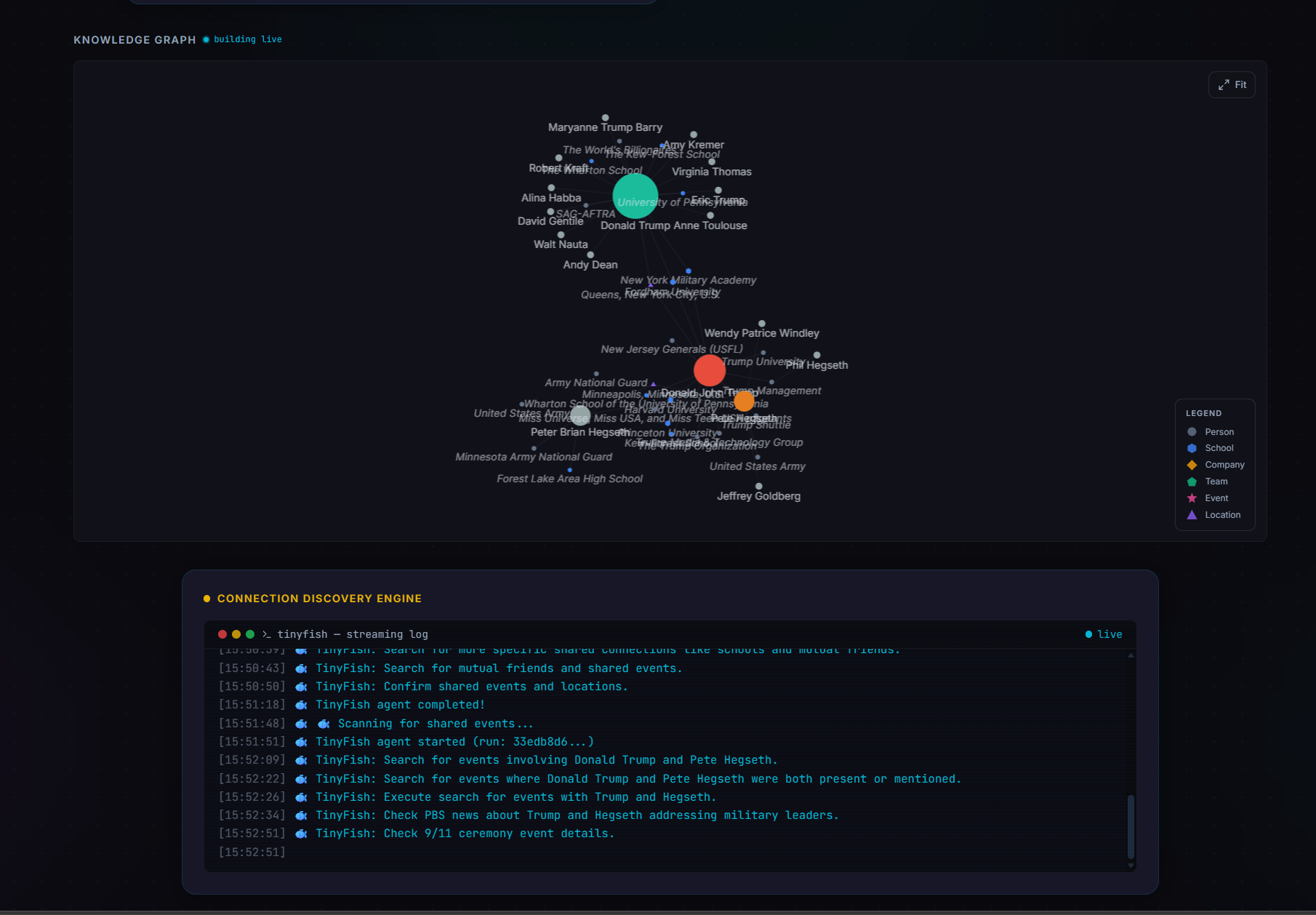
The deliberate call is that the path-finding itself is deterministic NetworkX. The LLM only extracts and summarises. Same input, same path, every time. We pay for the slow stealth browser exactly once per person, and only when the cheap layers don’t already have the answer. That’s why the demo holds up despite browser agents being slow. Most of the time, you’re not hitting the browser. You’re hitting a graph that someone else’s earlier search already built.
How we got here
Going into the TinyFish hackathon, my mental model of autonomous browser agents was: cool, finally something that can handle the boring half of every B2B workflow. Open this site, find this number, log into that dashboard, pull the data. It’s the demo every agent company is selling.
Reality, a few hours in: every action the agent takes is its own LLM call. It reasons, picks one click or one search, fires it, waits for the next reasoning step, repeats. TinyFish exposes a live view of the browser while the agent works, which is genuinely cool to watch and the most “the future is here” part of using it. It is also why the loop is slow. Every move is a model round-trip, every gated page is a captcha to negotiate, and the demo loop is minutes deep before you’ve returned anything interesting. Browser agents, today, are slow, bot-detected, and info-gated. The faster I accepted that, the faster the project went anywhere.
The first two pitches were respectable. A news scraper that watches a curated list of sources and surfaces signal versus noise. A supply chain disruption mapper that takes a company, walks its supplier and shipping graph, and flags reported incidents on any node. Both real problems. Both, on paper, the exact use case browser agents promise. Both died on speed and gating. Some sources worked fine, plenty threw captchas, and a surprising number sniffed out the headless browser within seconds. By the time the agent had hopped a few nodes through the supply graph, the demo loop was minutes deep and had returned a single half-useful insight. You cannot pitch that.
So we got unhinged and built TinyWorld. The pitch was “find out if you’re dating your cousin,” which got the laugh. The real product underneath is what TinyWorld surfaces: non-obvious second-degree closeness between people. Same investor across two companies. Shared advisor. Co-attendee at a niche event four years ago. A photo from a wedding that nobody flagged on either profile. The kind of connection that doesn’t show up if you just LinkedIn someone, but shows up if a patient agent spends ten minutes walking the public web on your behalf.
That is KYC. That is compliance. That is the “is this counterparty closer to my customer than they should be” question that banks, insurers, and onboarding teams run every day, slowly, by humans. The unhinged demo and the real product are the same product with a different audience.
How it landed
The cousin demo did its job. Most of the room was tickled, and a healthy fraction were visibly thinking about which of their own friends they’d run through it. The KYC reframe got real traction once we walked it out, and the consistent pushback was the right kind. Not “is this a real product,” but “how much of this data is actually scrapeable?” Which is the honest question. A lot of the connection signal that matters in real KYC, the HR records, family-tree data, private memberships, locked-down social graphs, lives behind logins or isn’t online at all. Public-web KYC is a real product. It’s also a thin slice of the full thing, and a serious version would need to pair it with the boring proprietary data sources you don’t get from a stealth browser.
The hot take
My read on the hackathon, take it for what it’s worth: TinyFish probably wasn’t shopping for product ideas. They were running a stress test. Hand a roomful of ambitious developers a credit-loaded API key, watch which workflows their agents survive and which ones make them faceplant, walk away with a week’s worth of failure modes for free. The TinyFish folks who came by our table openly acknowledged the system is slow, which is exactly what you’d expect from people running a load test rather than a sales demo. We were the load test. Honestly, fair trade.
What I’m taking away
Browser agents are real, just not for the use cases the marketing implies. Latency-sensitive workflows are out. Time-sensitive reads on gated sources are out. What works is patient, breadth-first crawls of low-stakes public surfaces where being slow doesn’t matter, because no human was going to do it anyway. That’s a smaller world than the pitch deck suggests. Still a real one.